OCR数据集¶
这里整理了OCR中常用的公开数据集,持续更新中,欢迎各位小伙伴贡献数据集~
1. 文本检测¶
1.1 PaddleOCR 文字检测数据格式¶
PaddleOCR 中的文本检测算法支持的标注文件格式如下,中间用"\t"分隔:
json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 points 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。
transcription 表示当前文本框的文字,当其内容为“###”时,表示该文本框无效,在训练时会跳过。
如果您想在我们未提供的数据集上训练,可以按照上述形式构建标注文件。
1.2 公开数据集¶
| 数据集名称 | 图片下载地址 | PaddleOCR 标注下载地址 |
|---|---|---|
| ICDAR 2015 | https://rrc.cvc.uab.es/?ch=4&com=downloads | train / test |
| ctw1500 | https://paddleocr.bj.bcebos.com/dataset/ctw1500.zip | 图片下载地址中已包含 |
| total text | https://paddleocr.bj.bcebos.com/dataset/total_text.tar | 图片下载地址中已包含 |
| td tr | https://paddleocr.bj.bcebos.com/dataset/TD_TR.tar | 图片下载地址中已包含 |
1.2.1 ICDAR 2015¶
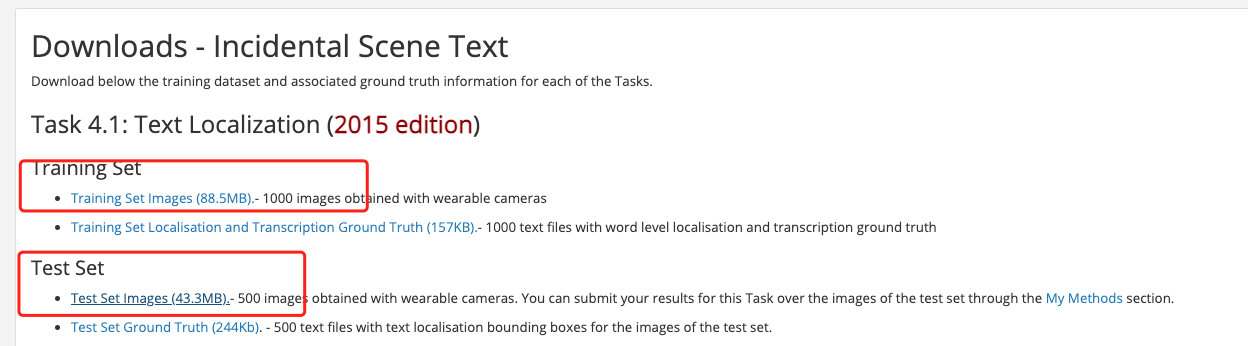
ICDAR 2015 数据集包含1000张训练图像和500张测试图像。ICDAR 2015 数据集可以从上表中链接下载,首次下载需注册。
注册完成登陆后,下载下图中红色框标出的部分,其中, Training Set Images下载的内容保存在icdar_c4_train_imgs文件夹下,Test Set Images 下载的内容保存早ch4_test_images文件夹下
将下载到的数据集解压到工作目录下,假设解压在 PaddleOCR/train_data/下。然后从上表中下载转换好的标注文件。
PaddleOCR 也提供了数据格式转换脚本,可以将官网 label 转换支持的数据格式。 数据转换工具在 ppocr/utils/gen_label.py, 这里以训练集为例:
解压数据集和下载标注文件后,PaddleOCR/train_data/ 有两个文件夹和两个文件,按照如下方式组织icdar2015数据集:
2. 文本识别¶
2.1 PaddleOCR 文字识别数据格式¶
PaddleOCR 中的文字识别算法支持两种数据格式:
lmdb用于训练以lmdb格式存储的数据集,使用 lmdb_dataset.py 进行读取;通用数据用于训练以文本文件存储的数据集,使用 simple_dataset.py进行读取。
下面以通用数据集为例, 介绍如何准备数据集:
训练集¶
建议将训练图片放入同一个文件夹,并用一个txt文件(rec_gt_train.txt)记录图片路径和标签,txt文件里的内容如下:
注意: txt文件中默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错。
最终训练集应有如下文件结构:
除上述单张图像为一行格式之外,PaddleOCR也支持对离线增广后的数据进行训练,为了防止相同样本在同一个batch中被多次采样,我们可以将相同标签对应的图片路径写在一行中,以列表的形式给出,在训练中,PaddleOCR会随机选择列表中的一张图片进行训练。对应地,标注文件的格式如下:
上述示例标注文件中,"11.jpg"和"12.jpg"的标签相同,都是简单可依赖,在训练的时候,对于该行标注,会随机选择其中的一张图片进行训练。
验证集¶
同训练集类似,验证集也需要提供一个包含所有图片的文件夹(test)和一个rec_gt_test.txt,验证集的结构如下所示:
2.2 公开数据集¶
| 数据集名称 | 图片下载地址 | PaddleOCR 标注下载地址 |
|---|---|---|
| en benchmark(MJ, SJ, IIIT, SVT, IC03, IC13, IC15, SVTP, and CUTE.) | DTRB | LMDB格式,可直接用lmdb_dataset.py加载 |
| ICDAR 2015 | http://rrc.cvc.uab.es/?ch=4&com=downloads | train/ test |
| 多语言数据集 | 百度网盘 提取码:frgi google drive |
图片下载地址中已包含 |
2.1 ICDAR 2015¶
ICDAR 2015 数据集可以在上表中链接下载,用于快速验证。也可以从上表中下载 en benchmark 所需的lmdb格式数据集。
下载完图片后从上表中下载转换好的标注文件。
PaddleOCR 也提供了数据格式转换脚本,可以将ICDAR官网 label 转换为PaddleOCR支持的数据格式。 数据转换工具在 ppocr/utils/gen_label.py, 这里以训练集为例:
数据样式格式如下,(a)为原始图片,(b)为每张图片对应的 Ground Truth 文本文件:

3. 数据存放路径¶
PaddleOCR训练数据的默认存储路径是 PaddleOCR/train_data,如果您的磁盘上已有数据集,只需创建软链接至数据集目录: