General Table Recognition Pipeline Tutorial¶
1. Introduction to the General Table Recognition Pipeline¶
Table recognition is a technology that automatically identifies and extracts table content and its structure from documents or images. It is widely used in data entry, information retrieval, and document analysis. By leveraging computer vision and machine learning algorithms, table recognition can convert complex table information into editable formats, facilitating further data processing and analysis for users.
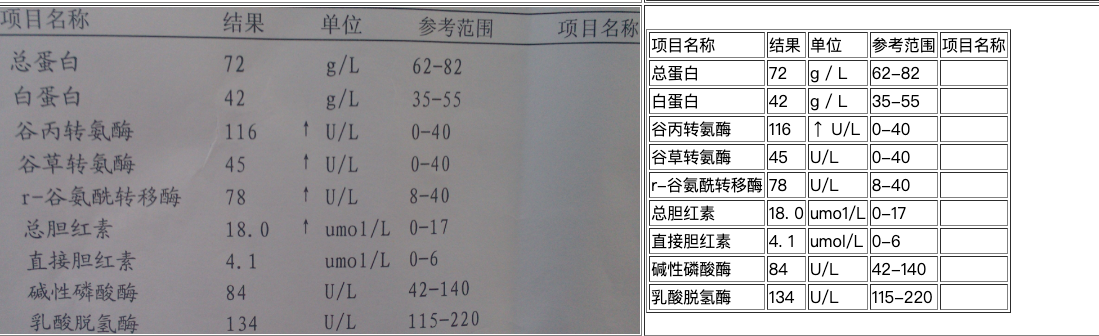 The General Table Recognition Pipeline comprises modules for table structure recognition, layout analysis, text detection, and text recognition.
If you prioritize model accuracy, choose a model with higher accuracy. If you prioritize inference speed, select a model with faster inference. If you prioritize model size, choose a model with a smaller storage footprint.
The General Table Recognition Pipeline comprises modules for table structure recognition, layout analysis, text detection, and text recognition.
If you prioritize model accuracy, choose a model with higher accuracy. If you prioritize inference speed, select a model with faster inference. If you prioritize model size, choose a model with a smaller storage footprint.
👉Model List Details
Table Recognition Module Models:
| Model | Model Download Link | Accuracy (%) | CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Size (M) | Description |
|---|---|---|---|---|---|---|
| SLANet | Inference Model/Trained Model | 59.52 | 103.08 / 103.08 | 197.99 / 197.99 | 6.9 M | SLANet is a table structure recognition model developed by Baidu PaddleX Team. The model significantly improves the accuracy and inference speed of table structure recognition by adopting a CPU-friendly lightweight backbone network PP-LCNet, a high-low-level feature fusion module CSP-PAN, and a feature decoding module SLA Head that aligns structural and positional information. |
| SLANet_plus | Inference Model/Trained Model | 63.69 | 140.29 / 140.29 | 195.39 / 195.39 | 6.9 M | SLANet_plus is an enhanced version of SLANet, a table structure recognition model developed by Baidu PaddleX Team. Compared to SLANet, SLANet_plus significantly improves its recognition capabilities for wireless and complex tables, while reducing the model's sensitivity to the accuracy of table localization. Even when there are offsets in table localization, it can still perform relatively accurate recognition. |
Layout Analysis Module Models:
| Model | Model Download Link | mAP(0.5) (%) | CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Size (M) | Description |
|---|---|---|---|---|---|---|
| PicoDet_layout_1x | Inference Model/Trained Model | 86.8 | 9.03 / 3.10 | 25.82 / 20.70 | 7.4 | An efficient layout area localization model trained on the PubLayNet dataset based on PicoDet-1x can locate five types of areas, including text, titles, tables, images, and lists. |
| PicoDet_layout_1x_table | Inference Model/Trained Model | 95.7 | 8.02 / 3.09 | 23.70 / 20.41 | 7.4 M | An efficient layout area localization model trained on the PubLayNet dataset based on PicoDet-1x can locate one type of tables. |
| PicoDet-S_layout_3cls | Inference Model/Trained Model | 87.1 | 8.99 / 2.22 | 16.11 / 8.73 | 4.8 | An high-efficient layout area localization model trained on a self-constructed dataset based on PicoDet-S for scenarios such as Chinese and English papers, magazines, and research reports includes three categories: tables, images, and seals. |
| PicoDet-S_layout_17cls | Inference Model/Trained Model | 70.3 | 9.11 / 2.12 | 15.42 / 9.12 | 4.8 | A high-efficient layout area localization model trained on a self-constructed dataset based on PicoDet-S_layout_17cls for scenarios such as Chinese and English papers, magazines, and research reports includes 17 common layout categories, namely: paragraph titles, images, text, numbers, abstracts, content, chart titles, formulas, tables, table titles, references, document titles, footnotes, headers, algorithms, footers, and seals. |
| PicoDet-L_layout_3cls | Inference Model/Trained Model | 89.3 | 13.05 / 4.50 | 41.30 / 41.30 | 22.6 | An efficient layout area localization model trained on a self-constructed dataset based on PicoDet-L for scenarios such as Chinese and English papers, magazines, and research reports includes three categories: tables, images, and seals. |
| PicoDet-L_layout_17cls | Inference Model/Trained Model | 79.9 | 13.50 / 4.69 | 43.32 / 43.32 | 22.6 | A efficient layout area localization model trained on a self-constructed dataset based on PicoDet-L_layout_17cls for scenarios such as Chinese and English papers, magazines, and research reports includes 17 common layout categories, namely: paragraph titles, images, text, numbers, abstracts, content, chart titles, formulas, tables, table titles, references, document titles, footnotes, headers, algorithms, footers, and seals. |
| RT-DETR-H_layout_3cls | Inference Model/Trained Model | 95.9 | 114.93 / 27.71 | 947.56 / 947.56 | 470.1 | A high-precision layout area localization model trained on a self-constructed dataset based on RT-DETR-H for scenarios such as Chinese and English papers, magazines, and research reports includes three categories: tables, images, and seals. |
| RT-DETR-H_layout_17cls | Inference Model/Trained Model | 92.6 | 115.29 / 104.09 | 995.27 / 995.27 | 470.2 | A high-precision layout area localization model trained on a self-constructed dataset based on RT-DETR-H for scenarios such as Chinese and English papers, magazines, and research reports includes 17 common layout categories, namely: paragraph titles, images, text, numbers, abstracts, content, chart titles, formulas, tables, table titles, references, document titles, footnotes, headers, algorithms, footers, and seals. |
Text Detection Module Models:
| Model Name | Model Download Link | Detection Hmean (%) | CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Size (M) |
|---|---|---|---|---|---|
| PP-OCRv4_mobile_det | Inference Model/Trained Model | 77.79 | 8.79 / 3.13 | 51.00 / 28.58 | 4.2 M |
| PP-OCRv4_server_det | Inference Model/Trained Model | 82.69 | 83.34 / 80.91 | 442.58 / 442.58 | 100.1M |
2. Quick Start¶
PaddleX's pre-trained model pipelines allow for quick experience of their effects. You can experience the effects of the General Image Classification pipeline online or locally using command line or Python.
2.1 Online Experience¶
You can experience online the effects of the General Table Recognition pipeline by using the demo images provided by the official. For example:
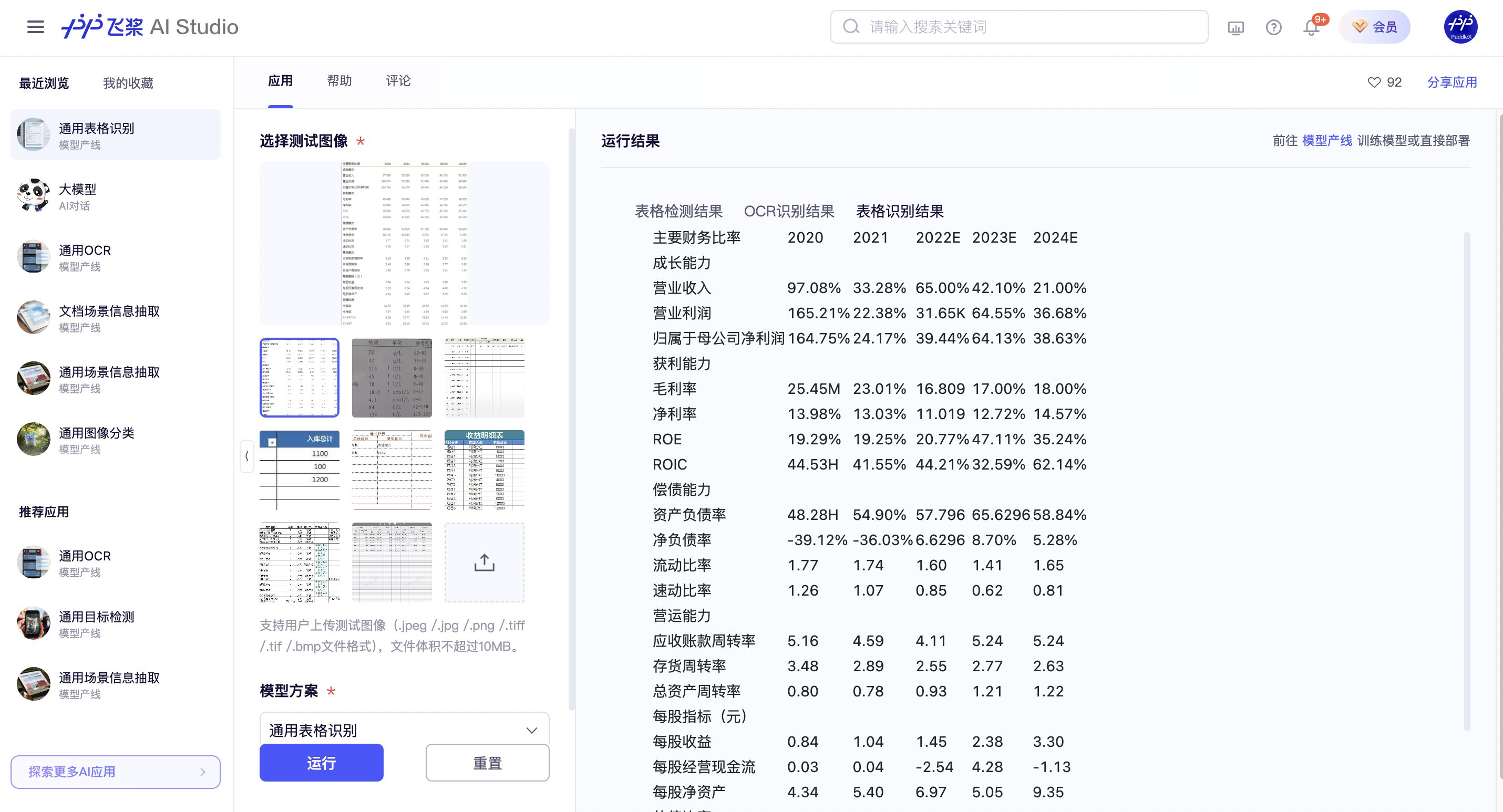
If you are satisfied with the pipeline's performance, you can directly integrate and deploy it. If not, you can also use your private data to fine-tune the models in the pipeline online.
2.2 Local Experience¶
Before using the General Table Recognition pipeline locally, ensure you have installed the PaddleX wheel package following the PaddleX Local Installation Guide.
2.1 Command Line Experience¶
Experience the effects of the table recognition pipeline with a single command:
Experience the image anomaly detection pipeline with a single command,Use the test file, and replace --input with the local path to perform prediction.
{kind=link}
--pipeline: The name of the pipeline, here it's the table recognition pipeline.
--input: The local path or URL of the input image to be processed.
--device: The GPU index to use (e.g., gpu:0 for the first GPU, gpu:1,2 for the 1st and 2nd GPUs). CPU can also be selected (--device cpu).
When executing the above command, the default table recognition pipeline configuration file is loaded. If you need to customize the configuration file, you can execute the following command to obtain it:
👉Click to expand
paddlex --get_pipeline_config table_recognition
After execution, the table recognition pipeline configuration file will be saved in the current directory. If you wish to customize the save location, you can execute the following command (assuming the custom save location is ./my_path):
paddlex --get_pipeline_config table_recognition --save_path ./my_path
After obtaining the pipeline configuration file, replace --pipeline with the configuration file save path to make the configuration file take effect. For example, if the configuration file save path is ./table_recognition.yaml, simply execute:
paddlex --pipeline ./table_recognition.yaml --input table_recognition.jpg --device gpu:0
Here, parameters like --model and --device do not need to be specified, as they will use the parameters in the configuration file. If they are still specified, the specified parameters will take precedence.
After running, the result is:

The visualized image not saved by default. You can customize the save path through --save_path, and then all results will be saved in the specified path.
2.2 Python Script Integration¶
A few lines of code are all you need to quickly perform inference with the pipeline. Taking the General Table Recognition pipeline as an example:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="table_recognition")
output = pipeline.predict("table_recognition.jpg")
for res in output:
res.print() # Print the structured output of the prediction
res.save_to_img("./output/") # Save the results in img format
res.save_to_xlsx("./output/") # Save the results in Excel format
res.save_to_html("./output/") # Save results in HTML format
In the above Python script, the following steps are executed:
(1)Instantiate the pipeline object using create_pipeline: Specific parameter descriptions are as follows:
| Parameter | Description | Type | Default |
|---|---|---|---|
pipeline |
The name of the pipeline or the path to the pipeline configuration file. If it is the name of the pipeline, it must be supported by PaddleX. | str |
None |
device |
The device for pipeline model inference. Supports: "gpu", "cpu". | str |
gpu |
config |
Specific configuration information for the pipeline (if set simultaneously with pipeline, it has higher priority than pipeline, and the pipeline name must be consistent with pipeline). |
dict[str, Any] |
None |
use_hpip |
Whether to enable high-performance inference, only available if the pipeline supports it. | bool |
False |
(2)Invoke the predict method of the pipeline object for inference prediction: The predict method parameter is x, which is used to input data to be predicted, supporting multiple input methods, as shown in the following examples:
| Parameter Type | Parameter Description |
|---|---|
| Python Var | Supports directly passing in Python variables, such as numpy.ndarray representing image data. |
| str | Supports passing in the path of the file to be predicted, such as the local path of an image file: /root/data/img.jpg. |
| str | Supports passing in the URL of the file to be predicted, such as the network URL of an image file: Example. |
| str | Supports passing in a local directory, which should contain files to be predicted, such as the local path: /root/data/. |
| dict | Supports passing in a dictionary type, where the key needs to correspond to a specific task, such as "img" for image classification tasks. The value of the dictionary supports the above types of data, for example: {"img": "/root/data1"}. |
| list | Supports passing in a list, where the list elements need to be of the above types of data, such as [numpy.ndarray, numpy.ndarray], ["/root/data/img1.jpg", "/root/data/img2.jpg"], ["/root/data1", "/root/data2"], [{"img": "/root/data1"}, {"img": "/root/data2/img.jpg"}]. |
(3)Obtain the prediction results by calling the predict method: The predict method is a generator, so prediction results need to be obtained through iteration. The predict method predicts data in batches, so the prediction results are in the form of a list.
(4)Process the prediction results: The prediction result for each sample is of dict type and supports printing or saving to files, with the supported file types depending on the specific pipeline. For example:
| Method | Description | Method Parameters |
|---|---|---|
| save_to_img | Save the results as an img format file | - save_path: str, the path to save the file. When it's a directory, the saved file name will be consistent with the input file type; |
| save_to_html | Save the results as an html format file | - save_path: str, the path to save the file. When it's a directory, the saved file name will be consistent with the input file type; |
| save_to_xlsx | Save the results as a spreadsheet format file | - save_path: str, the path to save the file. When it's a directory, the saved file name will be consistent with the input file type; |
Where save_to_img can save visualization results (including OCR result images, layout analysis result images, table structure recognition result images), save_to_html can directly save the table as an html file (including text and table formatting), and save_to_xlsx can save the table as an Excel format file (including text and formatting).
If you have a configuration file, you can customize the configurations of the image anomaly detection pipeline by simply modifying the pipeline parameter in the create_pipeline method to the path of the pipeline configuration file.
For example, if your configuration file is saved at ./my_path/table_recognition.yaml, you only need to execute:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="./my_path/table_recognition.yaml")
output = pipeline.predict("table_recognition.jpg")
for res in output:
res.print() # Print the structured output of prediction
res.save_to_img("./output/") # Save results in img format
res.save_to_xlsx("./output/") # Save results in Excel format
res.save_to_html("./output/") # Save results in HTML format
3. Development Integration/Deployment¶
If the pipeline meets your requirements for inference speed and accuracy in production, you can proceed with development integration/deployment.
If you need to directly apply the pipeline in your Python project, refer to the example code in 2.2 Python Script Integration.
Additionally, PaddleX provides three other deployment methods, detailed as follows:
🚀 High-Performance Inference: In actual production environments, many applications have stringent standards for deployment strategy performance metrics (especially response speed) to ensure efficient system operation and smooth user experience. To this end, PaddleX provides high-performance inference plugins that aim to deeply optimize model inference and pre/post-processing for significant end-to-end process acceleration. For detailed high-performance inference procedures, refer to the PaddleX High-Performance Inference Guide.
☁️ Serving: Serving is a common deployment strategy in real-world production environments. By encapsulating inference functions into services, clients can access these services via network requests to obtain inference results. PaddleX supports various solutions for serving pipelines. For detailed pipeline serving procedures, please refer to the PaddleX Pipeline Serving Guide.
Below are the API reference and multi-language service invocation examples for the basic serving solution:
API Reference
For the main operations provided by the service:
- The HTTP request method is POST.
- The request body and response body are both JSON data (JSON objects).
- When the request is processed successfully, the response status code is
200, and the attributes of the response body are as follows:
| Name | Type | Meaning |
|---|---|---|
logId |
string |
The UUID of the request. |
errorCode |
integer |
Error code. Fixed as 0. |
errorMsg |
string |
Error message. Fixed as "Success". |
result |
object |
The result of the operation. |
- When the request is not processed successfully, the attributes of the response body are as follows:
| Name | Type | Meaning |
|---|---|---|
logId |
string |
The UUID of the request. |
errorCode |
integer |
Error code. Same as the response status code. |
errorMsg |
string |
Error message. |
The main operations provided by the service are as follows:
infer
Locate and recognize tables in the image.
POST /table-recognition
- The properties of the request body are as follows:
| Name | Type | Meaning | Required |
|---|---|---|---|
file |
string |
The URL of an image file or PDF file accessible by the server, or the Base64 encoding result of the content of the above file types. For PDF files exceeding 10 pages, only the content of the first 10 pages will be used. | Yes |
fileType |
integer | null |
The file type. 0 represents a PDF file, and 1 represents an image file. If this attribute is not present in the request body, the file type will be inferred based on the URL. |
No |
useDocOrientationClassify |
boolean | null |
See the description of the use_doc_orientation_classify parameter in the predict method of the pipeline. |
No |
useDocUnwarping |
boolean | null |
See the description of the use_doc_unwarping parameter in the predict method of the pipeline. |
No |
useLayoutDetection |
boolean | null |
See the description of the use_layout_detection parameter in the predict method of the pipeline. |
No |
useOcrModel |
boolean | null |
See the description of the use_ocr_model parameter in the predict method of the pipeline. |
No |
layoutThreshold |
number | null |
See the description of the layout_threshold parameter in the predict method of the pipeline. |
No |
layoutNms |
boolean | null |
See the description of the layout_nms parameter in the predict method of the pipeline. |
No |
layoutUnclipRatio |
number | array | null |
See the description of the layout_unclip_ratio parameter in the predict method of the pipeline. |
No |
layoutMergeBboxesMode |
string | null |
See the description of the layout_merge_bboxes_mode parameter in the predict method of the pipeline. |
No |
textDetLimitSideLen |
integer | null |
See the description of the text_det_limit_side_len parameter in the predict method of the pipeline. |
No |
textDetLimitType |
string | null |
See the description of the text_det_limit_type parameter in the predict method of the pipeline. |
No |
textDetThresh |
number | null |
See the description of the text_det_thresh parameter in the predict method of the pipeline. |
No |
textDetBoxThresh |
number | null |
See the description of the text_det_box_thresh parameter in the predict method of the pipeline. |
No |
textDetUnclipRatio |
number | null |
See the description of the text_det_unclip_ratio parameter in the predict method of the pipeline. |
No |
textRecScoreThresh |
number | null |
See the description of the text_rec_score_thresh parameter in the predict method of the pipeline. |
No |
- When the request is processed successfully, the
resultin the response body has the following attributes:
| Name | Type | Description |
|---|---|---|
tableRecResults |
object |
The table recognition result. The length of the array is 1 (for image input) or the smaller of the number of document pages and 10 (for PDF input). For PDF input, each element in the array represents the processing result of each page in the PDF file. |
dataInfo |
object |
Information about the input data. |
Each element in tableRecResults is an object with the following attributes:
| Name | Type | Description |
|---|---|---|
prunedResult |
object |
The simplified version of the res field in the JSON representation generated by the predict method of the production object, with the input_path field removed. |
outputImages |
object | null |
A key-value pair of the input image and the predicted result image. The images are in JPEG format and encoded in Base64. |
inputImage |
string | null |
The input image. The image is in JPEG format and encoded in Base64. |
Multi-language service call example
Python
import base64
import requests
API_URL = "http://localhost:8080/table-recognition"
file_path = "./demo.jpg"
with open(file_path, "rb") as file:
file_bytes = file.read()
file_data = base64.b64encode(file_bytes).decode("ascii")
payload = {"file": file_data, "fileType": 1}
response = requests.post(API_URL, json=payload)
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["tableRecResults"]):
print(res["prunedResult"])
for img_name, img in res["outputImages"].items():
img_path = f"{img_name}_{i}.jpg"
with open(img_path, "wb") as f:
f.write(base64.b64decode(img))
print(f"Output image saved at {img_path}")
📱 Edge Deployment: Edge deployment is a method that places computing and data processing capabilities directly on user devices, allowing devices to process data without relying on remote servers. PaddleX supports deploying models on edge devices such as Android. For detailed edge deployment procedures, refer to the PaddleX Edge Deployment Guide. Choose the appropriate deployment method for your model pipeline based on your needs, and proceed with subsequent AI application integration.
4. Custom Development¶
If the default model weights provided by the general table recognition pipeline do not meet your requirements for accuracy or speed in your specific scenario, you can try to further fine-tune the existing model using your own domain-specific or application-specific data to improve the recognition performance of the general table recognition pipeline in your scenario.
4.1 Model Fine-tuning¶
Since the general table recognition pipeline consists of four modules, unsatisfactory performance may stem from any of these modules.
Analyze images with poor recognition results and follow the rules below for analysis and model fine-tuning:
- If the detected table structure is incorrect (e.g., row and column recognition errors, incorrect cell positions), the table structure recognition module may be insufficient. You need to refer to the Customization section in the Table Structure Recognition Module Development Tutorial and use your private dataset to fine-tune the table structure recognition model.
- If the table area is incorrectly located within the overall layout, the layout detection module may be insufficient. You need to refer to the Customization section in the Layout Detection Module Development Tutorial and use your private dataset to fine-tune the layout detection model.
- If many texts are undetected (i.e., text miss detection), the text detection model may be insufficient. You need to refer to the Customization section in the Text Detection Module Development Tutorial and use your private dataset to fine-tune the text detection model.
- If many detected texts contain recognition errors (i.e., the recognized text content does not match the actual text content), the text recognition model requires further improvement. You need to refer to the Customization section.
4.2 Model Application¶
After fine-tuning your model with a private dataset, you will obtain local model weights files.
To use the fine-tuned model weights, simply modify the pipeline configuration file by replacing the local path of the fine-tuned model weights to the corresponding location in the configuration file:
......
Pipeline:
layout_model: PicoDet_layout_1x # Can be modified to the local path of the fine-tuned model
table_model: SLANet # Can be modified to the local path of the fine-tuned model
text_det_model: PP-OCRv4_mobile_det # Can be modified to the local path of the fine-tuned model
text_rec_model: PP-OCRv4_mobile_rec # Can be modified to the local path of the fine-tuned model
layout_batch_size: 1
text_rec_batch_size: 1
table_batch_size: 1
device: "gpu:0"
......
5. Multi-Hardware Support¶
PaddleX supports various mainstream hardware devices such as NVIDIA GPU, Kunlun XPU, Ascend NPU, and Cambricon MLU. Simply modify the --device parameter to seamlessly switch between different hardware.
For example, if you use an NVIDIA GPU for table recognition pipeline inference, the Python command is:
At this time, if you want to switch the hardware to Ascend NPU, simply modify--device in the Python command to npu:
If you want to use the general table recognition pipeline on more types of hardware, please refer to the PaddleX Multi-Hardware Usage Guide.